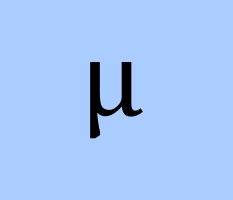
I see most of the content is focusing on tweaking ChatGPT models using prompt engineering. I agree, the bulk of the impact is in creative prompts. However, there are a few, more traditional parameters, that we often forget about. In this arcitle, I will cover the ones I found most useful for my work.
The goal of this article is not to provide comprehensive documentation of parameters but to point to the ones I found most important. Then readers can refer to the official documentation to get the details.
1. Temperature
Temperature is the parameter that I tune the most. It corresponds to randomness of output or how diverse the output can be. It ranges from 0 to 2. When it’s 0, the output will be deterministic, as the model always chooses the most likely token. At temperatures closer to 2, the output will be diverse and more “creative”.
2. Top_p - nucleus sampling
This is an alternative to temperature parameter. Instead of considering temperature, this parameter considers only outputs that are more likely with cumulative probability adding up to top_p. For example, if top_p = 0.2, it considers tokens that fall into 20% of the probability mass.
3. N - number of completions
This is number of completions, if you want to generate more than one response. Be careful, as it eats into your token budget.
4. Frequency and presence penalties
Frequency penalty penalises multiple use of the same word. Presence penalty does not consider number of times the word used but wheather it is being used or not, so it’s boolean in nature.
They are used directly in calculating logits. Here’s the formula:
mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
There are more parameters in the official documentation but these ones made the biggest difference in my experiments. If you think there is a missing one, please drop me a note, I’ll be happy to include it here :).
This article reflects my personal views and opinions only, which may be different from the companies and employers that I am associated with.