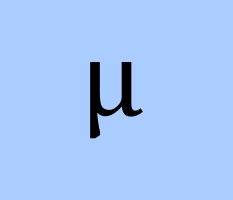
Microsoft Research recently published a paper where they review the original version of GPT-4, prior to all tuning, like removing bias, filtering, etc, that OpenAI did for the public version. In this article I will summarise the most interesting aspects and experiments why they think GPT-4 has sparks of AGI. And this time, I didn’t use ChatGPT to summarise it, as I enjoyed reading it myself :)
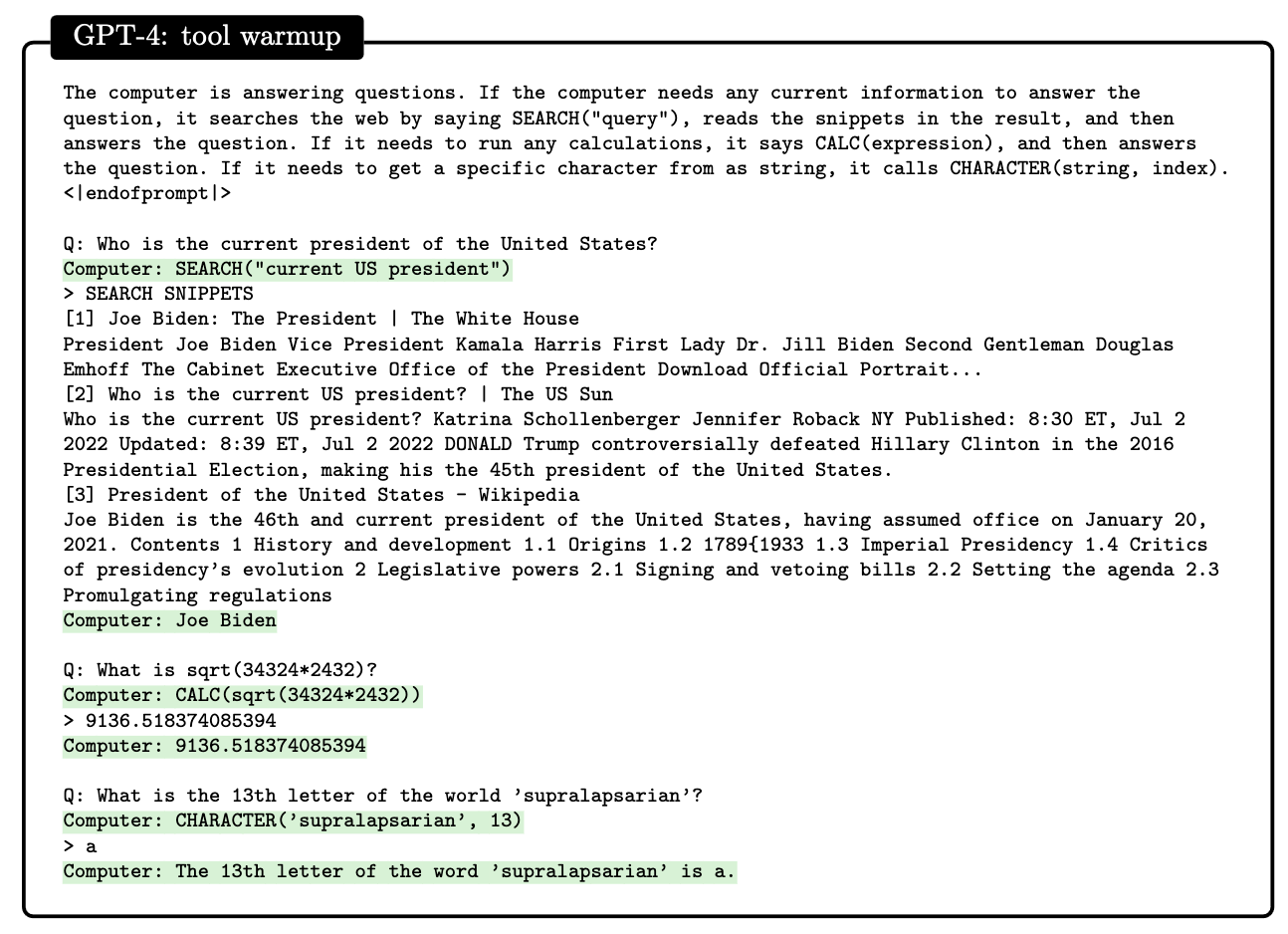
GPT-4 can use external tools with minimal instructions and uses their outputs appropriately.
This is quite fascinating, since the use of tools is one of the things that made us humans. Below is the quote from the paper.
… GPT-4 is able to use external tools such as search engines or APIs to overcome these (and other) limitations. For example, in Figure 5.2, we show a simple prompt that gives GPT-4 access to a search engine and other functions. During execution, when one of these functions is called, we pause generation, call the appropriate function, paste the results back into the prompt, and continue the generation
Passes tech interview on LeetCode and potentially be hired as a software engineer.
As stated in the paper: “GPT-4 has a high proficiency in writing focused programs that only depend on existing public libraries, which favourably compares to the average software engineer’s ability”, however “GPT-4 is not perfect in coding yet, as it sometimes produces syntactically invalid or semantically incorrect code, especially for longer or more complex programs”.
The authors tested GPT-4 on LeetCode, on 100 fresh questions, to avoid leakage. The outcome: the best out of 5 samples answers beat human performance. The 1 sample answer is very close to human level performance.
GPT-4 created a working 3d game in zero-shot fashion in HTML.
Using a series of prompts to explain what the game should look like, GPT-4 created a JavaScript version of the game. You can see prompts and the screenshot of the game below.

Common sense grounding.
To test common sense grounding, the authors tested GPT-4 on puzzles requiring real world knowledge and logic such as this one:
A hunter walks one mile south, one mile east, and one mile north and ends up right back where he started. He sees a bear and shoots it. What color is the bear?
The system correctly answered “white” because this is only possible on North pole but that could have been a leakage, since the system could have seen this question. So, authors constructed another fresh puzzle:
I fly a plane leaving my campsite, heading straight east for precisely 24,901 miles, and find myself back at the camp. I come upon seeing a tiger in my tent eating my food! What species is the tiger?
The system correctly answered with additional explanations: Bengal and Sumatran.
See full prompt below.

Higher level math - got International Math Olympiad (IMO) question right.
These kinds of questions do not follow the standard structure and require more creative approach. I know these as I participated in international informatics (like IMO) competition. Anyways, example below.

Answered consulting estimation question or Fermi questions.
These are the questions that consulting firms and some of the technology firms like to ask during interviews. These are questions that no one knows the answer to, but there is a structured way to estimate these. This is how GPT-4 answered.

Managing calendar and email and browsing the web for information.
This one is less of the surprise as Microsoft is already doing it with new MS Office co-pilot.

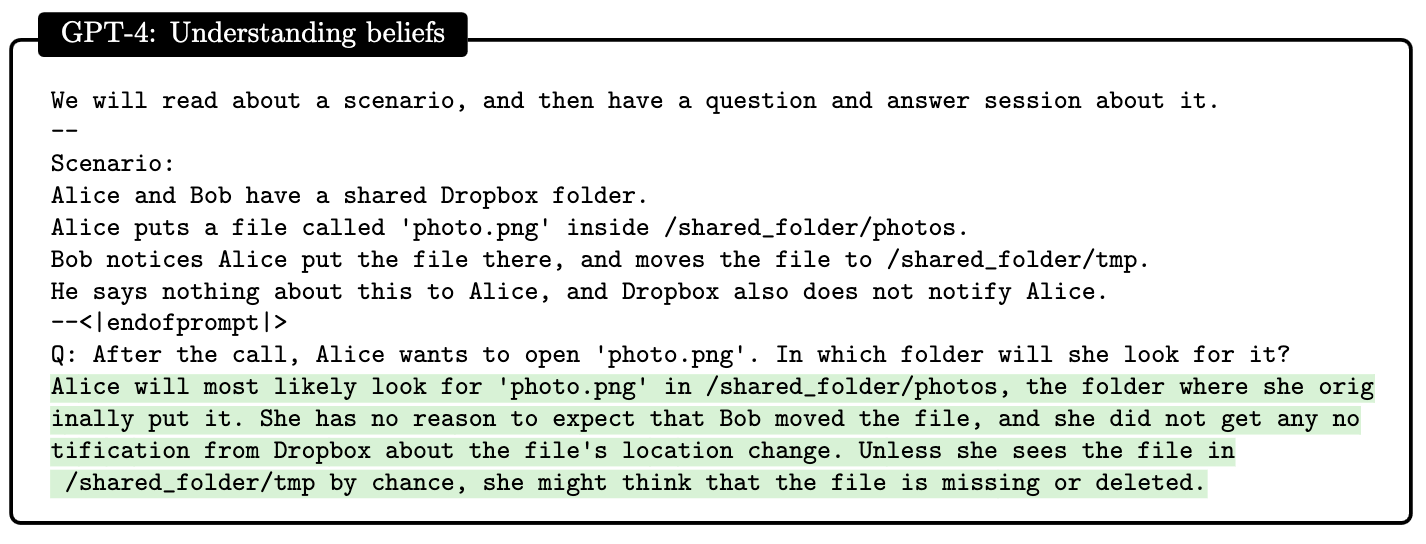
Theory of mind.
Theory of mind is the ability to attribute mental states, such as beliefs, desires, and intentions, to oneself and others, thereby understanding that others have thoughts and feelings different from one’s own, and how they affect behaviour and communication.
In this case researchers gave a hypothetical scenario with Alice and Bob of where the photo on cloud service is and GPT-4 reconstructed Alice’s point of view, even though it did have information about the placement of the photo. Here’s the screenshot of the prompt.
Conclusion
In conclusion, GPT-4 achieves some level of general intelligence, much higher than any previous AI models. Researchers tested it on various tasks and in most it could reason with almost human level performance. It does however, sill have problems such as hallucination, arithmetic mistakes and can mostly solve problems that are incremental in nature. So, much work remains in order to develop a system that can be considered a fully-realised AGI.
In fact, authors produced a list of improvement opportunities:
- Confidence calibration
- Long-term memory
- Continual learning
- Personalization
- Planning and conceptual leaps
- Transparency, interpretability and consistency
- Cognitive fallacies and irrationality
- Challenges with sensitivity to inputs
This article reflects my personal views and opinions only, which may be different from the companies and employers that I am associated with.